|
http://blog.csdn.net/freesum/article/details/7376006
������
? ? ? ? �������ǰ����ƵĶ���ͨ����̬����ķ����ֳɲ�ͬ�������߸�����Ӽ���subset��,��������ͬһ���Ӽ��еij�Ա���������Ƶ�һЩ���ԡ���?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ����wikipedia
? ? ? ?���������ָ��������������ļ��Ϸ����Ϊ�����ƵĶ�����ɵĶ����ķ������̡�����һ����Ҫ��������Ϊ�������ǽ����ݷ��ൽ��ͬ������ߴ�������һ�����̣�����ͬһ�����еĶ����кܴ�������ԣ�����ͬ�ؼ�Ķ����кܴ�������ԡ���
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?�����ٶȰٿ�
? ? ? ? �����⣬���һ�����ݼ��ϰ���N��ʵ��������ij������Խ���N��ʵ������Ϊm�����ÿ������е�ʵ��������صģ�����ͬ���֮���������Ҳ���Dz���صģ�������̾ͽо����ˡ�
�������
? ? ? ? ?1������ѡ��(feature selection)������������������һ��������������һ�л�Ļ��������ѡȡ�����������ܵı�����Ҫ�������Ϣ��һ����Ҫ���⡣������ǿ����������Ӱ�����Ч����������Ժ��ʵ�����һ�չʾ��
? ? ? ? ?2�����ڲ��(proximity measure)����ѡ����ʵ���������������������ж�����ʵ�����������أ���������Ƿdz��ؼ���һ�����⣬�ھ��������Ҳ���ž����Ե����壬��Ϊ���౾�������������벻���ƣ������ڲ�Ⱦ��Ƕ����������Ե�һ�ֶ��塣
? ? ? ?3��������(clustering criterion)�������������Ի���������Ͻ��ڲ�ȣ�����ж����Ʋ��ǹؼ���ֱ��������������������Ǻ�ʱ���࣬��ʱ������ľ���������������ʹ�þ����㷨���м���ʱ����ξ������㷨���ĵģ����������Ҫһ��������������������������˵���ⶫ��һ�ó������������˰�^_^��
? ? ? ?4�������㷨(clustering algorithm)�������������ϸ˵�˰ɣ�����ѧϰ������֮�أ����ĵĶ������ﲻ�����Ժ��ϸ˵������ͷ�������ý��ڲ�Ⱥ;�����ʼ����Ĺ��̡�
? ? ? ?5�������֤(validation of the results)����ʵ����PR����������������Ҳ�ŵ��������������У��Ҿ����е����࣬��Ϊ������֤�㷨����ȷ������Ӧ�÷ŵ��㷨����ɣ�����4����5�������һ�㡣��Ϊ�㷨��ȷ���������֤���������㷨���������˭�����һ���㷨����֤������
6��(interpretation of the results)�����İ��PR�Ϸ���Ϊ����ж������Ҹо�������˼���ǽ�����͡����������ջὫ���ݼ��ֳ����ɸ��࣬����ǰҪ��ԭ�����º�Ҫ�н��ͣ�������ǽ����ˡ���Բ��˵�����DZȽϺõ���^_^��
������
? ? ? ? ���������һ�������������ʾ��������һ�����ݼ��ϣ���ξ����ء���Ȼ����Ŀ�������кܶࡣ���磬������ǰ����꼶�Ƿ�Ϊ����1�����࣬��ô���ݼ�X��Ϊ���ࣺ{����}��{���ģ��ŷɣ�����}��������հ༶��ͬ���֣���Ϊ���ࣺ{����������}��{�ŷɣ�����}��������ճɼ��Ƿ����֣����輰��Ϊ60�֣��������ࣺ{���������ģ�����}��{�ŷ�}����Ȼ���������������Ǹ��ӵģ��Ϳ�������ô�����ˡ����նԷ���˼��ļ������⣬���ݼ��൱�������ռ䣬����ʵ��������������������4������[�������꼶���༶����ѧ�ɼ�]���൱�ڿռ�ά�ȣ���ʵ��������Ӧ���ռ��е�һ���㡣��ô�������Ӧ������Щ����ij�ƽ�棨��Ӧ����ѧ��������ʽ���Ҹ�����Ϊ��Щ�����͵�ͬ�ھ�������Щ��ƽ�潫���ݡ������ġ����뿪�ˡ�
������������
? ? ? ? ����ʱ�õ���������������أ���ʲô����Ҫ��������������֣����Է�Ϊ��������������ɢ��������������������Ӧ�Ķ����������ݿռ�R�������ӿռ䣬����ɢ������Ӧ������ɢ�Ӽ������������ɢ����ֻ������������ֵ����ô�����ɢ�����ֽж�ֵ������ ��������ȡֵ����������ֿ��Խ�������Ϊ�������֣�������(Nominal)��˳���(Ordinal)������߶ȵ�(Interval-scaled)�Լ����ʳ߶ȵ�(Ratio-scaled)�����У������������ڱ���һ�������Ŀ���״̬�������˵��Ա𣬱���Ϊ�к�Ů������״������Ϊ���������ȡ�˳������ͬ�����������ƣ�ͬ����һϵ��״̬�ı��룬ֻ�Ƕ���Щ�����Լ�Լ����������˳����������ģ������һ���ˣ�����������{���ѳԣ��ѳԣ�һ�㣬�óԣ���ζ}����ֵ������״̬��������Щ״̬����˳������ġ�������������Ϊ���DZ���������һ���ض��Ӽ���������һ����Լ���ı�������������߶�������ʾ��������ֵ֮����������������ֵ�ı��������壬�������Ӿ����¶ȣ�A�ص��¶ȣ�20�棩��B�أ�15�棩��5�ȣ�����������ֵ��������ģ����㲻��˵A�ر�B����1/3������������ġ�������������෴���������������ģ�����������������C��100g��D��50g����ôC��D��2��������������ġ�����Ȼ˵C��D��50gҲ�ǿ��Եģ���˿�����Ϊ����߶��DZ��ʳ߶ȵ�һ�����Ӽ�����
�ڳ���Ӧ���У���������ƽ�չ��ĵı��ʵ���У�һ��ֻ����nominal������numeric����������nominal������string����ʾ����numeric������number����ʾ����weka�е�attribute���������;�����ô����ģ�����weka�Ǹ��ö���WEKAʹ�ý̳�.pdf
�����㷨�ķ���
���ַ���
? ? ? ?���ַ������Ǹ����û�����ֵk�Ѹ�������ֳ�k�飨����2��������1. ÿ�������ٰ���һ������2. ÿ�����������ֻ����һ���飩��ÿ�鶼��һ�����࣬Ȼ������ѭ���ٶ�λ�����任��������Ķ���ֱ���ۻ��ֱ�������Ϊ���ƺ���������룩����Ϊֹ�����ʹ�����k-means,k-medoids ��εķ���
��εķ����Ը����Ķ��Ͻ��в�ηֽ⡣��Ϊ2�ࣺ���۵ĺͷ��ѵġ����۵ķ���Ҳ���Ե����ϵķ�������һ��ʼ��ÿ��������Ϊһ�������Ĵأ�Ȼ�����һ�������кϲ���ֱ�����ж���ϲ�Ϊһ���ػ�ﵽ��ֹ����Ϊֹ�����ѵķ���Ҳ���Զ����µķ�������һ��ʼ�����ж���ŵ�һ�����У�Ȼ����з��ѣ�ֱ�����ж���Ϊ������һ���ػ�ﵽ��ֹ����Ϊֹ�����ʹ�����CURE,BIRCH
�����ܶȵķ���
? ? ? �����ܶȵķ�����������������õľ���ֱ���ڽ��������ܶȳ���һ���ķ�ֵ����һ�������еĶ�������һ�������뾶�ڱ���������ٵĶ�������Ϊֹ�����ʹ�����DBSCAN��OPTICS��
��������ķ���
? ? ? ? ��������ķ�����������ռ仮��Ϊ������Ŀ�ĵ�Ԫ���γ�����ṹ�����о������������һ����ṹ�Ͻ��С����ʹ�����STING��?
����ģ�͵ķ���
? ? ? ? ����ģ�͵ķ�����Ϊÿ���������һ��ģ�ͣ�Ȼ����ģ��ȥ���ַ��ϵĶ��������ķ����������������ļ��裺�����Ǹ���DZ�ڵĸ��ʷֲ����ɵġ���Ҫ��2�ࣺͳ��ѧ�����������緽�������ʹ�����COBWEB��SOMs
��Ϊk-means
? ? ? ? ?K-means�㷨�Ǻܵ��͵Ļ��ھ���ľ����㷨�����þ�����Ϊ�����Ե�����ָ�꣬����Ϊ��������ľ���Խ���������ƶȾ�Խ���㷨��Ϊ�����ɾ��뿿���Ķ�����ɵģ���˰ѵõ������Ҷ����Ĵ���Ϊ����Ŀ�ꡣ
�� ? k����ʼ��������ĵ��ѡȡ�Ծ��������нϴ��Ӱ�죬��Ϊ�ڸ��㷨��һ�����������ѡȡ����k��������Ϊ��ʼ��������ģ���ʼ�ش���һ���ء����㷨��ÿ�ε����ж����ݼ���ʣ���ÿ��������������������ĵľ��뽫ÿ���������¸�������Ĵء����������������ݶ����һ�ε���������ɣ��µľ������ı���������������һ�ε���ǰ��J��ֵû�з����仯��˵���㷨�Ѿ�������
�㷨����
? ? ? ? 1����N���ĵ����ѡȡK���ĵ���Ϊ����
����2����ʣ���ÿ���ĵ������䵽ÿ�����ĵľ��룬�������鵽��������ĵ���
����3�����¼����Ѿ��õ��ĸ����������
����4������2��3��ֱ���µ�������ԭ������Ȼ�С��ָ����ֵ���㷨����
? ? ? ? ?˵�����£����ȴ�n�����ݶ�������ѡ�� k ��������Ϊ��ʼ�������ģ���������ʣ�����������������������Щ�������ĵ����ƶȣ����룩���ֱ����Ƿ�������������Ƶģ����������������ģ����ࣻȻ ���ټ���ÿ�������¾���ľ������ģ��þ��������ж���ľ�ֵ���������ظ���һ����ֱ������Ⱥ�����ʼ����Ϊֹ��һ�㶼���þ�������Ϊ����Ⱥ���. k��������������ص㣺�����౾�������ܵĽ��գ���������֮�価���ܵķֿ���
�����������£�
���� ���룺k,data[n];
������1�� ѡ��k����ʼ���ĵ㣬����c[0]=data[0],��c[k-1]=data[k-1]��
������2�� ����data[0]��.data[n]���ֱ���c[0]��c[k-1]�Ƚϣ��ٶ���c[i]��ֵ���٣��ͱ��Ϊi��
������3�� �������б��Ϊi�㣬���¼���c[i]={ ���б��Ϊi��data[j]֮��}/���Ϊi�ĸ�����
������4�� �ظ�(2)(3)��ֱ������c[i]ֵ�ı仯С�ڸ�����ֵ��
k-means �㷨ȱ��
�� ? ?�� �� K-means �㷨�� K �����ȸ����ģ���� K ֵ��ѡ���Ƿdz����Թ��Ƶġ��ܶ�ʱ�����Ȳ���֪�����������ݼ�Ӧ�÷ֳɶ��ٸ���������ʡ���Ҳ�� K-means �㷨��һ�����㡣�е��㷨��ͨ������Զ��ϲ��ͷ��ѣ��õ���Ϊ������������Ŀ K������ ISODATA �㷨������ K-means �㷨�о�����ĿK ֵ��ȷ���������У��Ǹ��ݷ���������ۣ�Ӧ�û�� F ͳ������ȷ����ѷ���������Ӧ����ģ������������֤��ѷ���������ȷ�ԡ��������У�ʹ����һ�ֽ��ȫЭ�������� RPCL �㷨������ɾ����Щֻ��������ѵ�����ݵ��ࡣ��������ʹ�õ���һ�ֳ�Ϊ��ʤ���ܷ��ľ���ѧϰ�������Զ���������ʵ���Ŀ������˼���ǣ���ÿ��������ԣ�����������ʤ��Ԫ��Ȩֵ����������Ӧ����ֵ�����ҶԴ�ʤ��Ԫ���óͷ��ķ���ʹ֮Զ������ֵ��
������ �� K-means �㷨�У�������Ҫ���ݳ�ʼ����������ȷ��һ����ʼ���֣�Ȼ��Գ�ʼ���ֽ����Ż��������ʼ�������ĵ�ѡ��Ծ������нϴ��Ӱ�죬һ����ʼֵѡ��IJ��ã��������õ���Ч�ľ���������Ҳ��Ϊ K-means�㷨��һ����Ҫ���⡣���ڸ�����Ľ���������㷨�����Ŵ��㷨��GA������������ �в����Ŵ��㷨��GA�����г�ʼ�������ڲ���������Ϊ����ָ�ꡣ
������ �� K-means �㷨��ܿ��Կ��������㷨��Ҫ���ϵؽ�������������������ϵؼ����������µľ������ģ���˵��������dz���ʱ���㷨��ʱ�俪���Ƿdz���ġ�������Ҫ���㷨��ʱ�临�ӶȽ��з������Ľ�������㷨Ӧ�÷�Χ���������дӸ��㷨��ʱ�临�ӶȽ��з������ǣ�ͨ��һ��������������ȥ���������ĵĺ�ѡ�������������У�ʹ�õ� K-means �㷨�Ƕ��������ݽ��о��࣬�����dz�ʼ���ѡ����һ�ε������ʱ�����ݵĵ��������ǽ��������ѡȡ���������ݵĻ���֮�ϣ�������������㷨�������ٶȡ�
��ΪTD��IDF
? ? ? ? TD��IDF��term frequency /inverse document frequency)��ֹһ�ο�����������ˣ�����ӡ�������������ڡ���ѧ֮�����ж���������Լ����������ѧ֮��.pdf
? ? ? ? TF-IDF��term frequency�Cinverse document frequency����һ��������Ѷ��������Ѷ̽���ij��ü�Ȩ������TF-IDF��һ��ͳ�Ʒ�������������һ�ִʶ���һ���ļ�����һ�����Ͽ��е�����һ���ļ�����Ҫ�̶ȡ��ִʵ���Ҫ�����������ļ��г��ֵĴ������������ӣ���ͬʱ�������������Ͽ��г��ֵ�Ƶ�ʳɷ����½���
? ? ? ? ?TF-IDF�㷨�ǽ���������һ������֮�ϵģ��������ĵ���������Ĵ���Ӧ������Щ���ĵ��г���Ƶ�ʸߣ����������ĵ����ϵ������ĵ��г���Ƶ���ٵĴ��������������ռ�����ϵȡTF��Ƶ��Ϊ��ȣ��Ϳ�������ͬ���ı����ص㡣���⿼�ǵ���������ͬ����������TFIDF����Ϊһ�����ʳ��ֵ��ı�Ƶ��ԽС��������ͬ����ı���������Խ��������������ı�Ƶ��IDF�ĸ����TF��IDF�ij˻���Ϊ�����ռ�����ϵ��ȡֵ��ȣ���������ɶ�ȨֵTF�ĵ���������Ȩֵ��Ŀ������ͻ����Ҫ���ʣ����ƴ�Ҫ���ʡ�
k-means ���ı�����
? ? ? ? ?ǰ�������TD��IDF���ǿ���ͨ����TD��IDF����ÿ���������ļ��е���Ҫ�̶ȡ��������ļ������ǵ��ļ��еĸ������ʵ���Ҫ�̶����ƣ��ҾͿ���˵��Щ�ļ������Ƶġ����������Щ�ļ������ƶ��أ�һ�ֺ���Ȼ���뷨�������ߵ�ŷ����þ�������Ϊ����ȣ�ŷ����þ���Ķ������£�

? ? ? ? ?�������������Ԫ����ŷ�Ͽռ��еļ��Ͼ��룬��Ϊ��ֱ�����ҿɽ�����ǿ�����㷺���ڱ�ʶ��������Ԫ�ص�����ȡ����ǿ��Խ�X��Y�ֱ�����Ϊ��ƪ�ı��ļ���xi,y��ÿ���ļ����ʵ�TD��IDFֵ�������Ϳ���������ļ������ƶ��ˡ��������ǿ��Խ��ļ����������ת��Ϊһ���Եľ�����̣������ռ��е�����ľ������ŷʽ������������ŷ�Ͼ����⣬������������������ȵĻ��������پ�����ɿɷ�˹�����룬���߶������£�
? ? ? ?�����پ��룺
? ? ? �ɿɷ�˹�����룺
? ? ? ? ? ? ? ? ? ?

? ? ? ? ?�����ı�������̿����Ⱥ��Ϊ������1�������ı����ϸ����ĵ���TD��IDFֵ��2�����ݼ���Ľ�������ļ�������k-means��������е������ࡣ
- TD-IDF�ļ���
�����ĵ�����T ����n|tn,n>1����
- ���ĵ����зִʻ�Tokennize������ȥ��ͣ�ôʡ�
- ��������ʳ��ֵĴ���freq(wi),��TF(i) = freq(wi)/sum( freq(w1..n)),��ʱ��sum( freq(w1..n))������max( freq(w1..n))������һ������
- ͳ���ļ��������д�wj���ֵ��ļ�����doc_freq(wj).��IDF�� 1/log(doc_freq(wj);
- ��������ļ������ǿ�������ļ�i������wj��TD��IDFȨֵW[i][j]= TD(j)*IDF(j)������iΪ�ļ�����T�е�һ���ļ�����j���ļ�����T�е�һ�����ʡ�
ͨ�����ļ�����T�ļ������ǿ��Եõ�һ����ά����(����)W[i][j].
- K-means����ĵ�������
- 1�����ѡȡk���ļ�����k������cluster,k���ļ��ֱ��Ӧ��k������ľ�������Mean(cluster) = k ;��Ӧ�IJ���Ϊ��W[i][j]��0��i�ķ�Χ��ѡk�У�ÿһ�д���һ�����������ֱ�����k�����࣬��ʹ�þ��������meanΪ���С�
- 2.��W[i][j]��ÿһ�У��ֱ����������k���������ĵľ��루ͨ��ŷ�Ͼ��룩distance(i,k)��
- 3.��W[i][j]��ÿһ�У��ֱ�������������һ���������ĵ�n(i) = ki��
- 4.�ж�W[i][j]��ÿһ���������������Ƿ����ھ��࣬���������������n(i)����������ǵ�Ŀǰ�����ľ�����������������������һ����
- 5.����n(i) ��������i���뵽����k�У����¼������ÿ���������ģ�ȥ�����и���������ƽ��ֵ����������2����
�����еĹ���k-means,TD-IDF�ĸ����������ֲο��˰ٶȰٿƣ�����wiki��������
���༭��PHP����� - �Ƹ�վ������
����������վ���ݾ��������磬��������۽��������߸��˹۵㣬��������վ�������������ַ�������Ȩ�����뼰ʱ����ϵվ��ɾ���������!
|



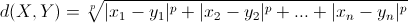

 �㹫������ 33038102330482��
�㹫������ 33038102330482��